
On October 7, 2025, we confronted a disruption in our e-mail service: some customers had been unable to obtain mail and entry mailboxes as a result of an sudden technical drawback in our storage system. All through the incident, your information was by no means in danger – our engineers prioritized information safety whereas fastidiously restoring full performance.

We all know how essential a dependable e-mail service is and sincerely apologize for the disruption. The remainder of this submit explains what occurred, how we resolved it, and what steps we’re taking to make our programs stronger.
What occurred
We use CEPH, a distributed storage system trusted by main organizations similar to CERN, and designed for top availability and information security.
The foundation trigger was associated to BlueFS allocator fragmentation, triggered by an unusually excessive quantity of small-object operations and metadata writes underneath heavy load.
In different phrases, the inside metadata house inside CEPH grew to become fragmented, which precipitated some object storage daemons (OSDs) to cease functioning accurately though the system had loads of free house accessible.
Incident timeline
All occasions are on October 7, 2025 (UTC):
- 09:17 – Monitoring programs alerted us about irregular habits in a single OSD node, and the engineering group instantly started investigating.
- 09:25 – Extra OSDs started displaying instability (“flapping”). The cluster was briefly configured to not mechanically take away unstable nodes, stopping pointless information rebalancing that might worsen efficiency.
- 09:30 – OSDs repeatedly failed to start out, getting into crash loops. Preliminary diagnostics dominated out {hardware} and capability points – disk utilization was under advisable thresholds.
- 10:42 – Debug logs revealed a failure within the BlueStore allocator layer, confirming a problem inside the RocksDB/BlueFS subsystem.
- 10:45 – Engineers started conducting a number of restoration checks, together with filesystem checks and tuning useful resource limits. The checks confirmed there have been no filesystem errors, however OSDs continued crashing throughout startup. Up thus far, there have been no issues for e-mail service customers.
- 11:00 – A Statuspage was created.
- 13:12 – The group hypothesized that the inner metadata house had develop into too fragmented and determined to prolong the RocksDB metadata quantity to supply extra room for compaction.
- 13:55 – Further NVMe drives had been first put in in a single OSD server to check whether or not including extra space would remediate the fragmentation situation.
- 15:02 – After validating the answer, extra NVMe drives had been put in on the remaining affected servers to broaden metadata capability.
- 15:10 – Engineers began performing on-site migrations of RocksDB metadata to the newly put in NVMe drives.
- 16:30 – The primary OSD efficiently began after migration – confirming the repair – and we carried out the identical migration and verification course of throughout the remaining OSDs.
- 19:17 – The storage cluster stabilized, and we began progressively bringing the infrastructure again on-line.
- 20:07 – All e-mail programs grew to become absolutely operational, and cluster efficiency has normalized (see the picture under). Crucially, all incoming emails had been efficiently transferring from the queue to customers’ inboxes, permitting customers to entry and skim their emails.
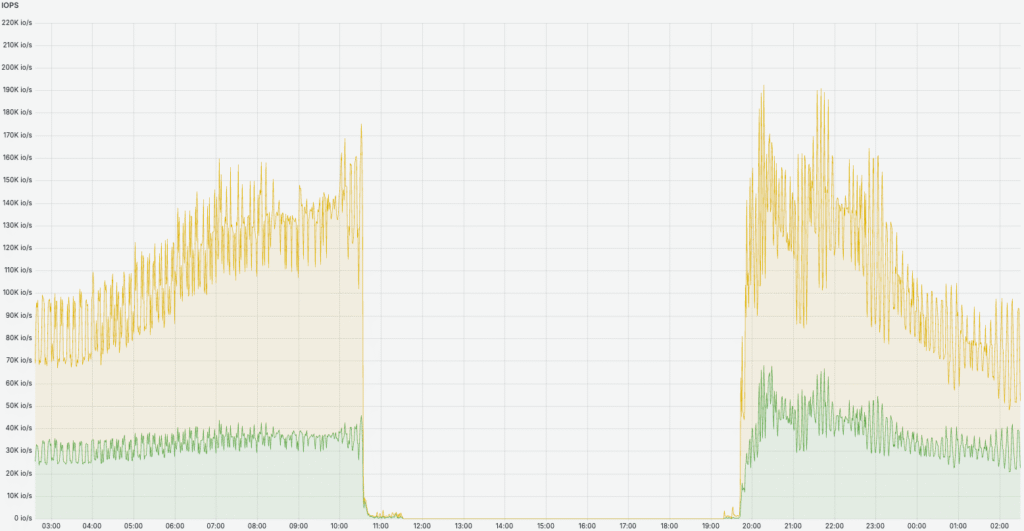
- 00:29 (October 8) – All queued incoming emails had been delivered to the corresponding customers’ mailboxes, and customers had been in a position to entry their mailboxes.
Full technical background
The problem was attributable to BlueFS allocator exhaustion, influenced by the default parameter bluefs_shared_alloc_size = 64K and triggered by an unusually excessive quantity of small-object operations and metadata writes underneath heavy load.
Below these metadata-heavy workloads, the inner metadata house inside CEPH grew to become fragmented – the allocator ran out of contiguous blocks to assign, though the drive itself nonetheless had loads of free house. This precipitated some object storage daemons (OSDs) to cease functioning accurately.
As a result of CEPH is designed to guard information by way of replication and journaling, no information loss occurred – your information remained utterly protected all through the incident. The restoration course of targeted on migrating and compacting metadata moderately than rebuilding consumer information.
Our response and subsequent steps
As soon as we recognized the reason for the problem, our engineers targeted on restoring service safely and shortly. Our group prioritized defending your information first, even when that meant the restoration took longer. Each restoration step was dealt with with care and totally validated earlier than execution.
Due to our resilient structure, all incoming emails had been efficiently delivered as soon as the storage system was restored, and no emails had been misplaced.
Our work doesn’t cease with restoring service – we’re dedicated to creating our infrastructure stronger for the long run.
To enhance efficiency and resilience, we put in devoted NVMe drives on each OSD server to host RocksDB metadata. This considerably boosted I/O pace and diminished metadata-related load.
We additionally strengthened our monitoring and alerting programs to trace fragmentation ranges and allocator well being extra successfully, enabling us to detect comparable situations earlier.
We additionally captured detailed logs and metrics, and we’re collaborating carefully with the CEPH builders to share our findings and contribute enhancements that may assist the broader group keep away from comparable points and make the system much more resilient.
We recognize your persistence and understanding as we labored by way of this incident. Thanks for trusting us – we’ll continue to learn, bettering, and making certain that your companies keep quick, dependable, and safe. And for those who want any assist, our Buyer Success group is right here for you 24/7.








 Makes NASADAQ Prime Gainer Checklist")

{kind=link}