

Half the “open-source” fashions individuals suggest on Reddit would make Richard Stallman’s eye twitch. Llama makes use of a Neighborhood license with strict utilization restrictions, and Gemma comes with Phrases of Service that it is best to completely learn earlier than transport something with it.
The time period itself has develop into meaningless on account of overuse, so earlier than we suggest any software program, let’s first make clear the definition.
What you really need are open-weight fashions. Weights are the downloadable “brains” of the AI. Whereas the coaching information and strategies would possibly stay a commerce secret, you get the half that issues: a mannequin that runs fully on {hardware} you management.
What’s the Distinction Between Open-Supply, Open-Weights, and Phrases-Based mostly AI?
“Open” is a spectrum in trendy AI that requires cautious navigation to keep away from authorized pitfalls.
We’ve damaged down the three major classes that outline the present ecosystem to make clear precisely what you’re downloading.
| Class | Definition | Typical Licenses | Business Security |
| Open Supply AI (Strict) | Meets the Open Supply Initiative (OSI) definition; you get the weights, coaching information, and the “most popular kind” to change the mannequin. | OSI-Accredited | Absolute; you have got whole freedom to make use of, research, modify, and share. |
| Open-Weights | You may obtain and run the “mind” (weights) domestically, however the coaching information and recipe usually stay closed. | Apache 2.0, MIT | Excessive; usually protected for business merchandise, fine-tuning, and redistribution. |
| Supply-Out there/Phrases-Based mostly | Weights are downloadable, however particular authorized phrases strictly dictate how, the place, and by whom they can be utilized. | Llama Neighborhood, Gemma Phrases | Restricted; usually contains utilization thresholds (e.g., >700M customers) and acceptable use insurance policies. |
Why Does the Definition of “Open” Matter?
Open-weights fashions entered a extra mature section someplace round mid-2025. “Open” more and more means not simply downloadable weights, however how a lot of the system you may examine, reproduce, and govern.
- Open is a spectrum: In AI, “open” isn’t a sure/no label. Some tasks open weights, others open coaching recipes, and others open evaluations. The extra of the stack you may examine and reproduce, the extra open it truly is.
- The purpose of openness is sovereignty: The true worth of open-weight fashions is their management. You may run them the place your information lives, tune them to your workflows, and maintain working even when distributors change pricing or insurance policies.
- Open means auditable: Openness doesn’t magically take away bias or hallucinations, however what it does provide you with is the flexibility to audit the mannequin and apply your individual guardrails.
💡Professional tip: For those who’re uncertain what class the mannequin you picked falls into, do a fast sanity examine. Discover the mannequin card on Hugging Face, scroll to the license part, and browse it. Apache 2.0 is normally the most secure selection for business deployment.
How Does GPU Reminiscence Decide Which Fashions You Can Run?
No one chooses the “greatest” mannequin available on the market. Folks select the mannequin that most closely fits their VRAM with out crashing. The benchmarks are irrelevant if a mannequin requires 48GB of reminiscence and you’re operating an RTX 4060.
To keep away from losing time on testing unimaginable suggestions, listed here are three distinct elements that devour your GPU reminiscence throughout inference:
- Mannequin weights: That is your baseline value. An 8-billion parameter mannequin at full precision (FP16) wants roughly 16GB simply to load — double the parameters, double the reminiscence.
- Key-value cache: This grows with each phrase you kind. Each token processed allocates reminiscence for “consideration,” that means a mannequin that masses efficiently would possibly nonetheless crash midway via an extended doc if you happen to max out the context window.
- Overhead: Frameworks and CUDA drivers completely reserve one other 0.5GB to 1GB. That is non-negotiable, and that reminiscence is just gone.
Nevertheless, if you wish to run bigger parameter fashions, look into quantization. Quantizing the load precision from 16-bit to 4-bit can shrink a mannequin’s footprint by roughly 75% with barely any loss in high quality.
The trade normal — Q4_K_M (GGUF format) — retains about 95% of the unique efficiency for chat and coding whereas lowering the reminiscence necessities.
What Can You Count on From Totally different VRAM Configurations?
Your VRAM tier dictates your expertise, from quick, easy chatbots to near-frontier reasoning capabilities. This fast desk is a practical have a look at what you may run.
| GPU VRAM | Comfy Mannequin Measurement (Quantized) | What to Count on |
| 8GB | ~3B to 7B parameters | Quick responses, fundamental coding help, and easy chat. |
| 12GB | ~7B to 10B parameters | The “Every day Driver” candy spot; strong reasoning, good instruction following. |
| 16GB | ~14B to 20B parameters | A noticeable functionality bounce; higher code era and complicated logic. |
| 24GB+ | ~27B to 32B parameters | Close to-frontier high quality; slower era, however nice for RAG and lengthy paperwork. |
🤓Nerd be aware: Context size can blow up reminiscence quicker than you anticipate. A mannequin that runs effective with 4K context would possibly choke at 32K. So, don’t max out context until you’ve completed the mathematics.
The ten Greatest Self-Hosted AI Fashions You Can Run at House
We’re grouping these by VRAM tier as a result of that’s what really issues. Benchmarks come and go, however your GPU’s reminiscence capability is a bodily fixed.
Greatest Self-Hosted AI Fashions for 12GB VRAM
For the 12GB tier, you’re searching for effectivity. You need fashions that punch above their weight class.

1. Ministral 3 8B
Launched in December 2025, this instantly turned the mannequin to beat at this dimension. It’s Apache 2.0 licensed, multimodal (can course of photographs together with textual content), and optimized for edge deployment. Mistral educated it alongside their bigger fashions, which you’ll discover within the output high quality.
✅Verdict: Ministral is the effectivity king; its distinctive tendency towards shorter, extra exact solutions makes it the quickest general-purpose mannequin on this class.
2. Qwen3 8B
From Alibaba, this mannequin ships with a characteristic no person else has discovered but: hybrid pondering modes. You may instruct it to assume via complicated issues step-by-step or disable reasoning for fast responses. It incorporates a 128K context window and was the primary mannequin household educated particularly for the Mannequin Context Protocol (MCP).
✅Verdict: Probably the most versatile 8B mannequin obtainable, particularly optimized for agentic workflows the place the AI must deal with complicated instruments or exterior information.
3. Llama 3.1 8B Instruct
This stays the ecosystem default. Each framework helps it, and each tutorial makes use of it for instance. Nevertheless, be aware the license: Meta’s neighborhood settlement will not be open-source, and strict utilization phrases apply.
✅Verdict: The most secure wager for compatibility with tutorials and instruments, supplied you have got learn the Neighborhood License and confirmed your use case complies.
4. Qwen2.5-Coder 7B Instruct
This mannequin exists for only one function: writing code. Skilled particularly on programming duties, it outperforms most of the bigger general-purpose fashions on code-generation benchmarks whereas requiring much less reminiscence.
✅Verdict: The trade normal for a neighborhood pair programmer; use this if you would like Copilot-like solutions with out sending proprietary code to the cloud.
Greatest Self-Hosted AI Fashions for 16GB VRAM
Transferring to 16GB means that you can run fashions that provide a real inflection level in reasoning. These fashions don’t simply chat; they resolve issues.
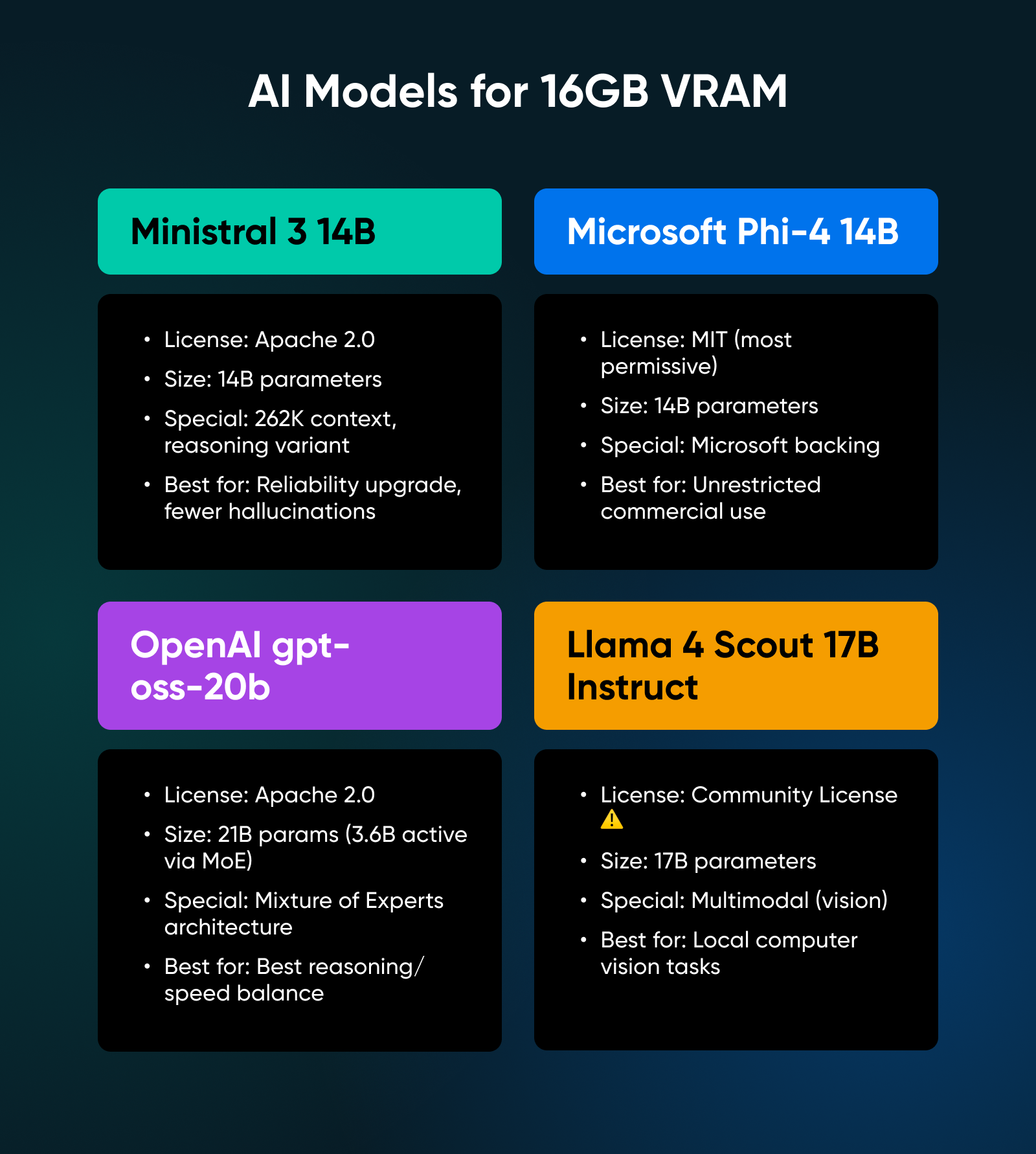
5. Ministral 3 14B
This scales up the structure of the 8B model with the identical give attention to effectivity. It provides a 262K context window and a reasoning variant that hits 85% on AIME 2025 (a contest math benchmark).
✅Verdict: A real reliability improve over the 8B class; the additional VRAM value pays off considerably in decreased hallucinations and higher instruction following.
6. Microsoft Phi-4 14B
Phi-4 ships beneath the MIT license, probably the most permissive possibility obtainable. No utilization restrictions in any respect; it provides robust efficiency on reasoning duties and boasts Microsoft’s backing for long-term assist.
✅Verdict: The legally most secure selection; select this mannequin in case your major concern is an unrestrictive license for business deployment.
7. OpenAI gpt-oss-20b
After 5 years of closed-source improvement, OpenAI launched this open-weight mannequin with an Apache 2.0 license. It makes use of a Combination of Specialists (MoE) structure, that means it has 21 billion parameters however solely makes use of 3.6 billion energetic parameters per token.
✅Verdict: A technical marvel that delivers one of the best stability of reasoning functionality and inference velocity within the 16GB tier.
8. Llama 4 Scout 17B Instruct
Meta’s newest launch of the Llama mannequin improves upon the multimodal capabilities launched to the Llama household in model 3, permitting you to add photographs and ask questions on them.
✅Verdict: The perfect and most polished possibility for native laptop imaginative and prescient duties, permitting you to course of paperwork, receipts, and screenshots securely by yourself {hardware}.
Greatest Self-Hosted AI Fashions for 24GB+ VRAM
If in case you have an RTX 3090 or 4090, you enter the “Energy Consumer” tier, the place you may run fashions that strategy frontier-class efficiency.
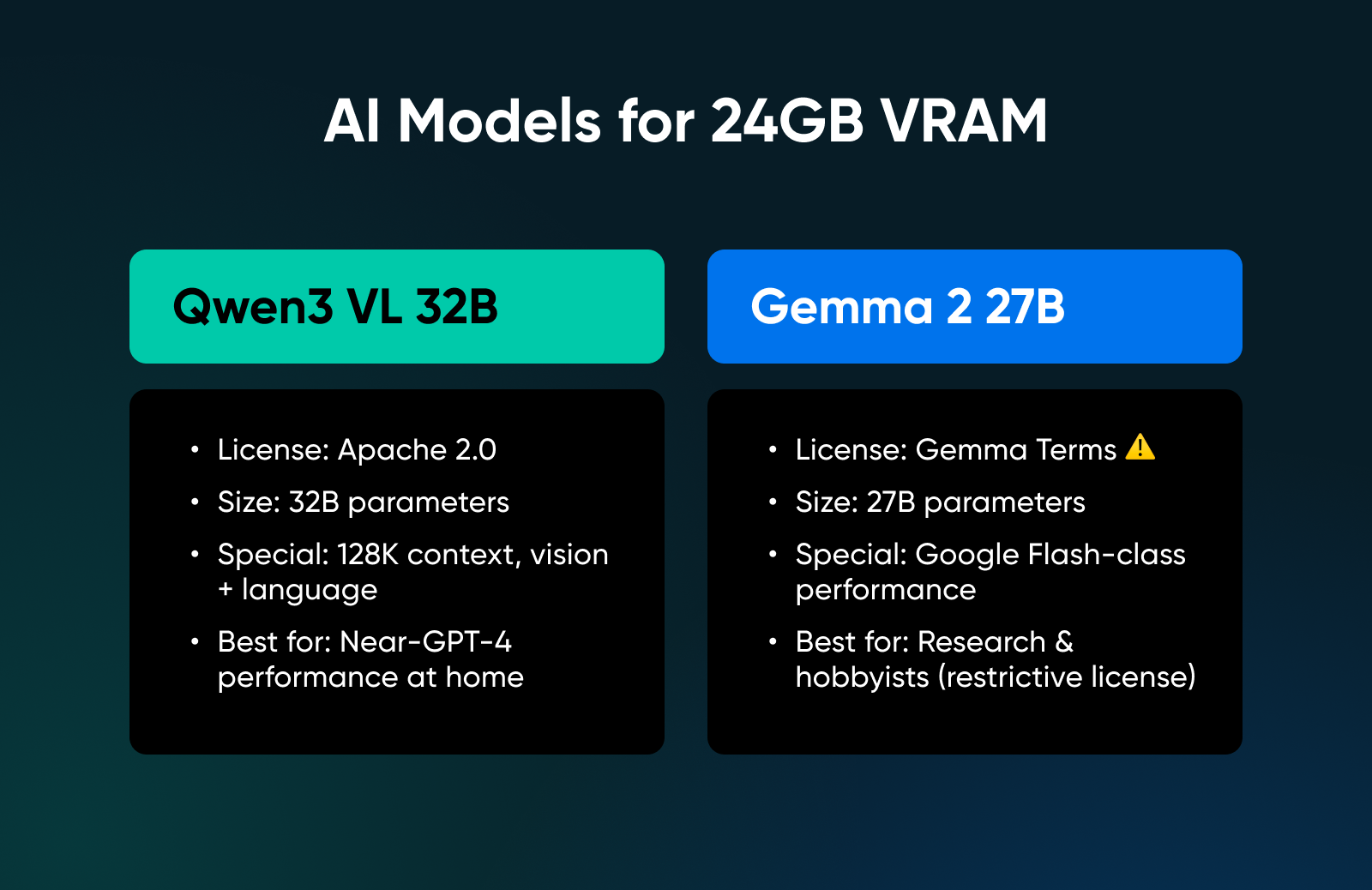
9. Qwen3 VL 32B
This mannequin targets the 24GB candy spot particularly. It provides nearly every little thing you’d want: Apache 2.0 licensed, 128K context, imaginative and prescient and language mannequin with efficiency matching the earlier era’s 72B mannequin.
✅Verdict: Absolutely the restrict of single-GPU native deployment; that is as near GPT-4 class efficiency as you may get at house with out shopping for a server.
10. Gemma 2 27B
Google has launched a bunch of actually robust Gemma fashions, of which this one is the closest to their Flash fashions obtainable on-line. However be aware that this mannequin isn’t multi-modal; it does nonetheless supply robust language and reasoning efficiency.
✅Verdict: A high-performance mannequin for researchers and hobbyists, although the restrictive license makes it a tough promote for business merchandise.
Bonus: Distilled Reasoning Fashions
We have to say fashions like DeepSeek R1 Distill. These exist at a number of sizes and are derived from bigger mum or dad fashions to “assume” (spend extra tokens processing) earlier than answering.
Such fashions are good for particular math or logic duties the place accuracy issues greater than latency. Nevertheless, licensing relies upon fully on the bottom mannequin lineage, the place some variants are derived from Qwen (Apache 2.0), whereas others are derived from Llama (Neighborhood License).
All the time learn the precise mannequin card earlier than downloading to substantiate you’re compliant.
You have got the {hardware} and the mannequin. Now, how do you really run it? Three instruments dominate the panorama for several types of customers:
1. Ollama
Ollama is extensively thought-about the usual for “getting it operating tonight.” It bundles the engine and mannequin administration right into a single binary.
- The way it works: You put in it, kind ollama run llama3 or one other mannequin identify from the library, and also you’re chatting in seconds (relying on the mannequin dimension and your VRAM).
- The killer characteristic: Simplicity — it abstracts away all of the quantization particulars and file paths, making it the right place to begin for learners.
2. LM Studio
LM Studio supplies a GUI for individuals who choose to not reside in terminals. You may visualize your mannequin library and handle configurations with out memorizing command-line arguments.
- The way it works: You may seek for fashions, obtain them, configure quantization settings, and run a neighborhood API server with just a few clicks.
- The killer characteristic: Automated {hardware} offloading; it handles built-in GPUs surprisingly properly. In case you are on a laptop computer with a modest devoted GPU or Apple Silicon, LM Studio detects your {hardware} and mechanically splits the mannequin between your CPU and GPU.
3. llama.cpp Server
If you would like the uncooked energy of open-source with none “walled backyard,” you may run llama.cpp immediately utilizing its built-in server mode. That is usually most popular by energy customers as a result of it eliminates the intermediary.
- The way it works: You obtain the llama-server binary, level it at your mannequin file, and it spins up a neighborhood net server — it’s light-weight and has zero pointless dependencies.
- The killer characteristic: Native OpenAI compatibility; with a easy command, you immediately get an OpenAI-compatible API endpoint. You may plug this immediately into dictation apps, VS Code extensions, or any instrument constructed for ChatGPT, and it simply works.
When Ought to You Transfer From Native {Hardware} to Cloud Infrastructure?

Native deployment has limits, and realizing them saves you money and time.
Single-user workloads run nice domestically, as a result of it’s you and your laptop computer in opposition to the world. Privateness’s absolute, latency’s low, and you’ve got value zero after {hardware}. Nevertheless, multi-user eventualities get sophisticated quick.
Two individuals querying the identical mannequin would possibly work, 10 individuals is not going to. GPU reminiscence doesn’t multiply if you add customers. Concurrent requests queue up, latency spikes, and everybody will get annoyed. Moreover, lengthy context plus velocity creates unimaginable tradeoffs. KV cache scales linearly with context size — processing 100K tokens of context eats VRAM that could possibly be operating inference.
If you might want to construct a manufacturing service, the tooling modifications:
- vLLM: Gives high-throughput inference with OpenAI-compatible APIs, production-grade serving, and optimizations client instruments skip (like PagedAttention).
- SGLang: Focuses on structured era and constrained outputs, important for purposes that should output legitimate JSON.
These instruments anticipate server-grade infrastructure. A devoted server with a highly effective GPU makes extra sense than attempting to reveal your own home community to the web.
Right here’s a fast approach to determine:
- Run native: In case your aim is one consumer, privateness, and studying.
- Hire infrastructure: In case your aim is a service + concurrency + reliability.
Begin Constructing Your Self-Hosted LLM Lab Right now
You run fashions at house since you need zero latency, zero API payments, and whole information privateness. However your GPU turns into the bodily boundary. So, if you happen to attempt to drive a 32B mannequin into 12GB of VRAM, your system will crawl or crash.
As a substitute, use your native machine to prototype, fine-tune your prompts, and vet mannequin conduct.
As soon as you might want to share that mannequin with a group or assure it stays on-line whilst you sleep, cease preventing your {hardware} and transfer the workload to a devoted server designed for twenty-four/7 uptime.
You continue to get the privateness of native as devoted servers solely log hours of use, not what you chat with the hosted mannequin. And also you additionally skip the upfront {hardware} prices and setup.
Listed below are your subsequent steps:
- Audit your VRAM: Open your job supervisor or run nvidia-smi. That quantity determines your mannequin record. All the pieces else is secondary.
- Take a look at a 7B mannequin: Obtain Ollama or LM Studio. Run Qwen3 or Ministral at 4-bit quantization to determine your efficiency baseline.
- Establish your bottleneck: In case your context home windows are hitting reminiscence limits or your fan appears like a jet engine, consider if you happen to’ve outgrown native internet hosting. Excessive-concurrency duties belong on devoted servers, and you could simply must make the change.

Final in Energy, Safety, and Management
Devoted servers from DreamHost use one of the best {hardware} and software program obtainable to make sure your website is all the time up, and all the time quick.
Ceaselessly Requested Questions About Self-Hosted AI Fashions
Can I run an LLM on 8GB VRAM?
Sure. Qwen3 4B, Ministral 3B, and different sub-7B fashions run comfortably. Quantize to This fall and maintain context home windows cheap. Efficiency received’t match bigger fashions, however practical native AI is totally attainable on entry-level GPUs.
What mannequin ought to I exploit for 12GB?
Ministral 8B is the effectivity winner. And if you happen to’re doing heavy agentic work or tool-use, Qwen3 8B handles the Mannequin Context Protocol (MCP) higher than the rest on this weight class.
What’s the distinction between open-source and open-weights?
Open-source (strict definition) means you have got every little thing wanted to breed the mannequin: coaching information, coaching code, weights, and documentation.
Open-weights means you may obtain and run the mannequin, however coaching information and strategies could also be proprietary.
When ought to I exploit hosted inference as an alternative of native?
When the mannequin doesn’t slot in your VRAM, even when quantized — when you might want to serve a number of concurrent customers, when context necessities exceed what your GPU can deal with, or if you want service-grade reliability with SLOs and assist.
Did you take pleasure in this text?








{kind=link}