
When Claude Sonnet 4.5 launched in September 2025, it broke a number of the prevailing prompts. Not as a result of the discharge was buggy. However as a result of Anthropic had rebuilt how Claude follows directions.

Earlier variations would infer your intent and increase on imprecise requests. Claude 4.x takes you actually and does precisely what you ask for, nothing extra.
To grasp the brand new strategies, we evaluated 25 standard immediate engineering strategies in opposition to Anthropic’s docs, group experiments, and real-world deployments to search out which prompts really work higher with Claude 4.x. These 5 strategies
What Modified in Claude 4.5 That Broke Present Prompts?
Claude 4.5 fashions prioritize exact directions over “useful” guessing.
The earlier variations would fill within the blanks for you. When you requested for a “dashboard,” they assumed you wished charts, filters, and knowledge tables.
Claude 4.5 takes you actually. When you ask for a dashboard, it’d provide you with a clean body with a title since you didn’t ask for the remaining.
Anthropic clearly states: “Clients who need the ‘above and past’ conduct may have to extra explicitly request these behaviors.”
So, we have to cease treating the mannequin like a magic wand and begin treating it like a literal-minded worker.
The 5 Confirmed Methods That Measurably Enhance Claude’s Efficiency
Based mostly on our analysis, these 5 strategies constantly delivered noticeable enhancements in Claude’s efficiency for the duties we threw at it.
1. Structured and Labeled Prompts
Claude Sonnet 4.5’s system immediate makes use of structured prompts in all places. Simon Willison dug into the system prompts and located sections wrapped in tags like
In truth, you can edit “Kinds” to see Anthropic’s structured prompting in motion.
What we will infer is, Claude was skilled on structured prompts and is aware of find out how to parse them. XML works nice, so does JSON or different labeled prompting.
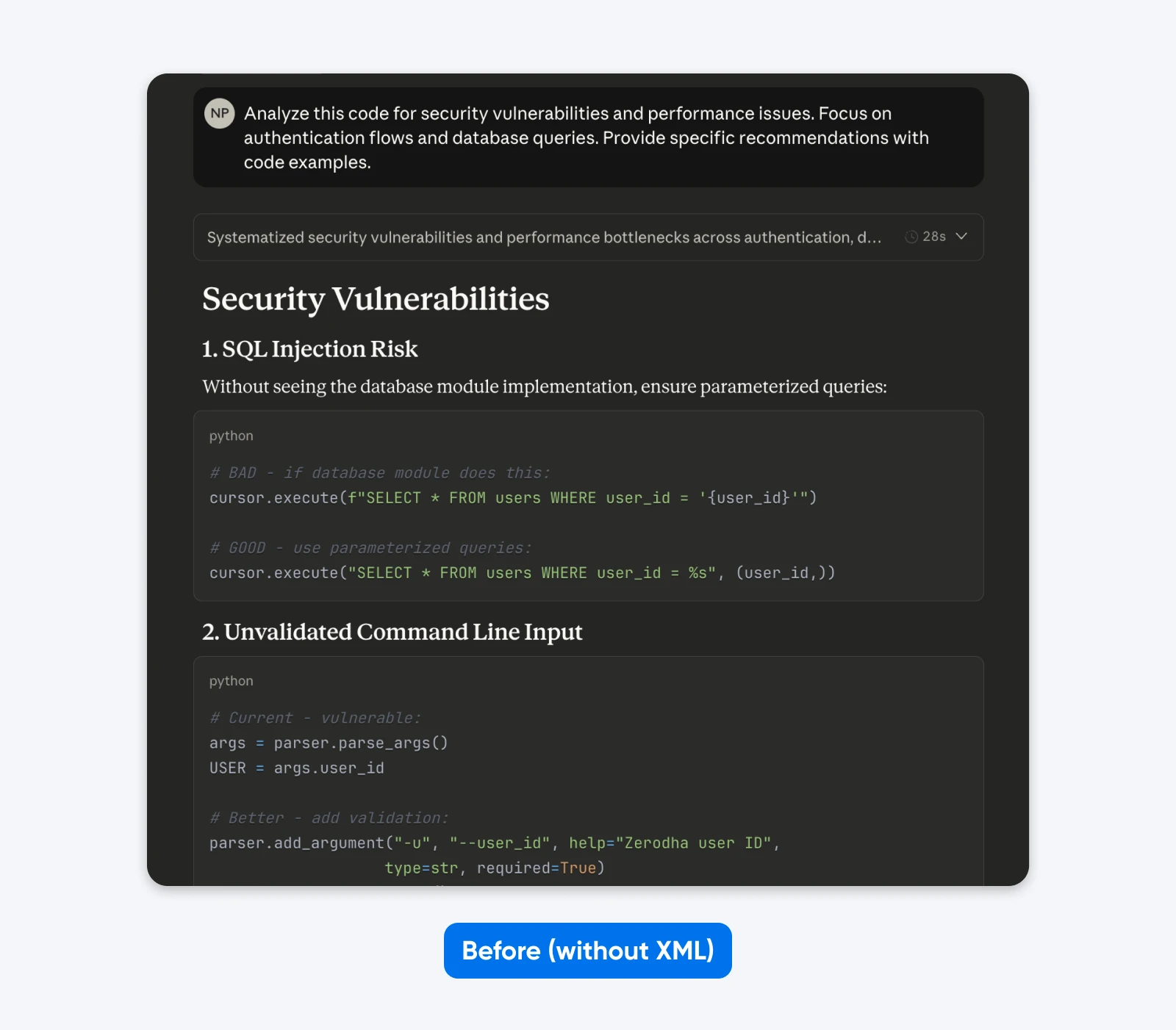
Earlier than:
Analyze this code for safety vulnerabilities and efficiency points. Give attention to authentication flows and database queries. Present particular suggestions with code examples.
After (structured immediate):
– Authentication flows
– Database question optimization
[your code here]
– Establish particular vulnerabilities with severity rankings
– Present corrected code examples
– Prioritize suggestions by enterprise impression
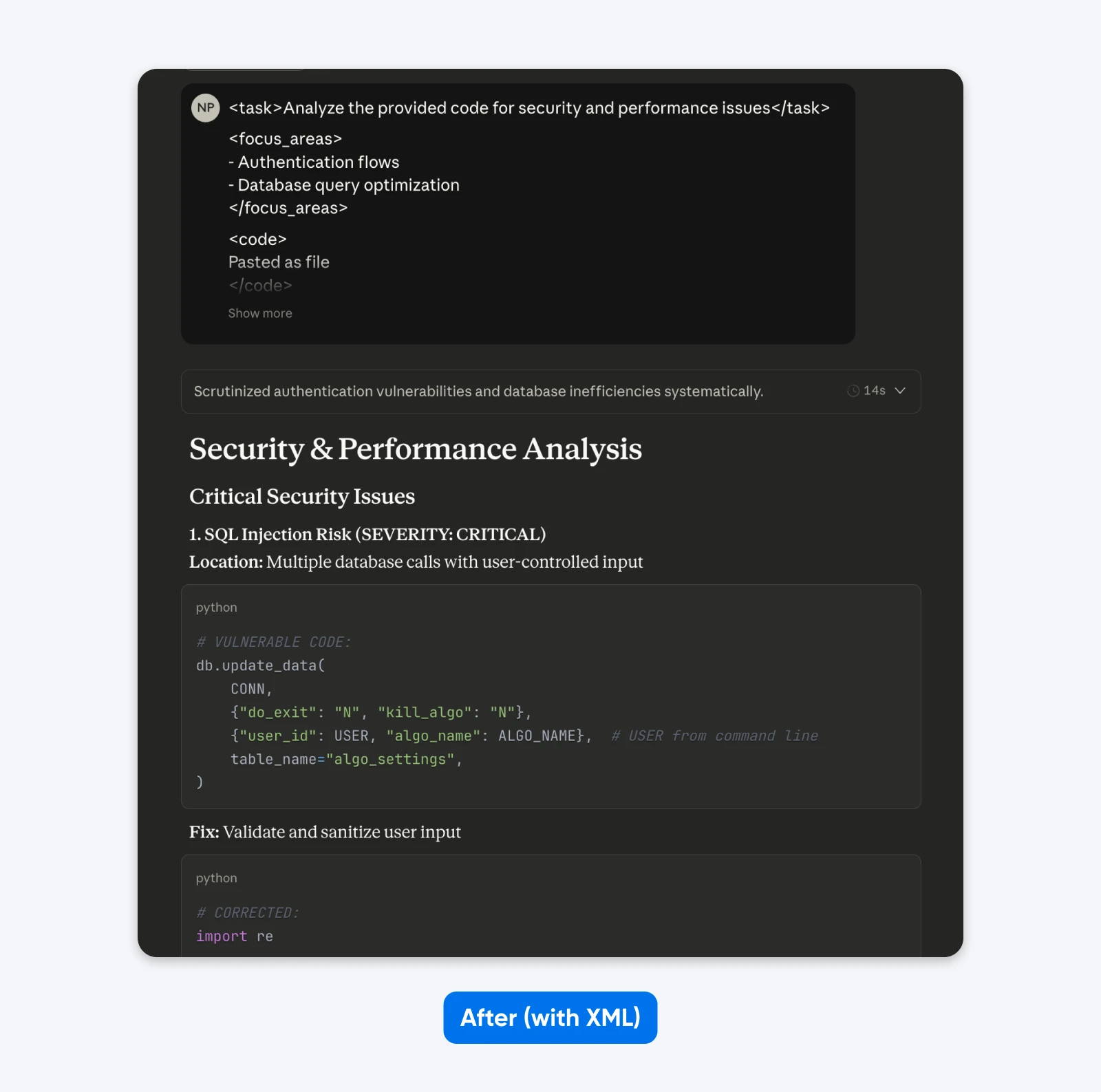
When you evaluate these outputs, you’ll discover that the structured immediate provides an output with extra context that can assist you perceive and repair the safety points within the code. It explains the difficulty, tells what the repair does, after which gives the code repair.
Different Codecs That Work:
JSON:
{
"job": "Overview authentication code",
"focus_areas": ["Password hashing", "Session security", "SQL injection"],
"context": "Healthcare app, HIPAA required",
"output_format": "Threat, impression, repair, severity per vulnerability"
}
Clear Headers:
TASK: Overview authentication code for vulnerabilities
FOCUS: Password hashing, classes, SQL injection
CONTEXT: Healthcare app requiring HIPAA compliance
OUTPUT FORMAT: Threat → HIPAA impression → Repair → Severity
All three work equally nicely.
When structured prompts work finest:
- A number of immediate elements (job, context, examples, necessities)
- Lengthy inputs (10,000+ tokens of code or paperwork)
- Sequential workflows with distinct steps
- Duties requiring repeated reference to particular sections
When to skip structured prompts: Easy questions the place plain textual content works superb.
Effectiveness score: 9/10 for complicated duties, 5/10 for easy queries.
2. Prolonged Considering for Complicated Issues
Prolonged Considering delivers huge enhancements on complicated reasoning duties with one main tradeoff: velocity.
Anthropic’s Claude 4 announcement confirmed substantial efficiency positive aspects with prolonged pondering enabled. On the AIME 2025 math competitors, scores improved considerably.
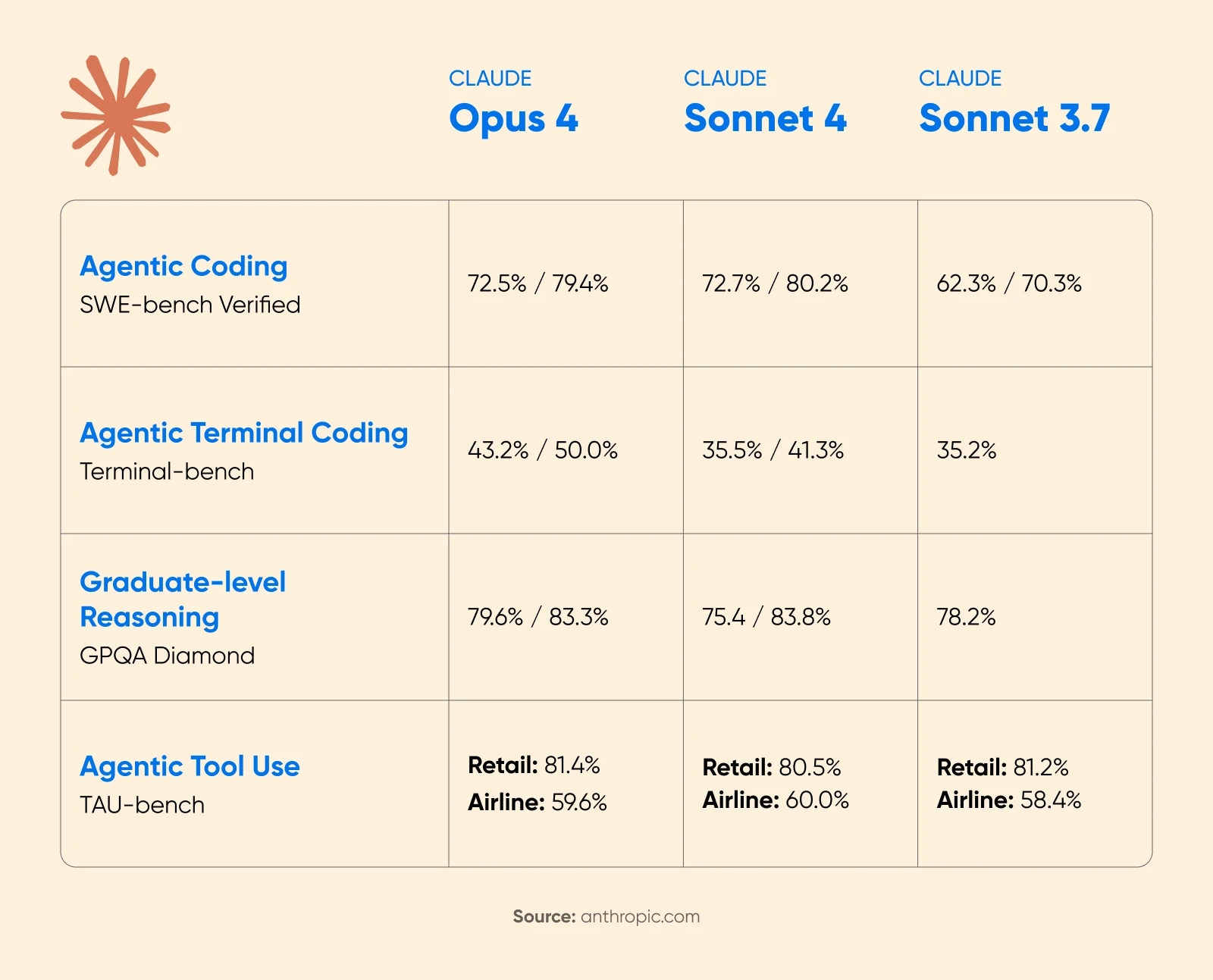
Cognition AI reported an 18% enhance in planning efficiency with Sonnet 4.5, calling it “the largest soar we’ve seen since Claude Sonnet 3.6.”
Earlier than (Normal mode):
Remedy this logic puzzle: 5 homes in a row, every a unique coloration…
After (with Prolonged Considering):
Perceive the logic of this puzzle systematically. Undergo the constraints step-by-step, checking every chance earlier than reaching conclusions.
5 homes in a row, every a unique coloration…
You gained’t see a lot distinction with easy prompts just like the one above. However for complicated, area of interest issues (customized codebases, multi-step logical planning), the distinction turns into clear.
When prolonged factor works:
- Multi-step logical planning requiring verification
- Mathematical reasoning with a number of resolution paths
- Complicated coding duties spanning a number of information
- Conditions the place correctness issues greater than velocity
When to Skip: Fast iterations, easy queries, inventive writing, time-sensitive duties
Effectiveness score: 10/10 for complicated reasoning, 3/10 for easy queries.
3. Be Brutally Particular About Necessities
Claude 4 fashions have been skilled for extra exact instruction-following than earlier generations.
Anthropic’s documentation says:
“Claude 4.x fashions reply nicely to clear, express directions. Being particular about your required output will help improve outcomes. Clients who need the ‘above and past’ conduct from earlier Claude fashions may have to extra explicitly request these behaviors with newer fashions.”
The documentation additionally notes that Claude is wise sufficient to generalize from the reason once you present context for why guidelines exist fairly than simply stating instructions. This implies offering a rationale helps the mannequin apply ideas appropriately in edge circumstances not explicitly coated.
Testing by 16x Eval confirmed that each Opus 4 and Sonnet 4 scored 9.5/10 on TODO duties when directions clearly specified necessities, format, and success standards. The fashions demonstrated spectacular conciseness and instruction-following capabilities.
Earlier than (implicit expectations):
Create an analytics dashboard.
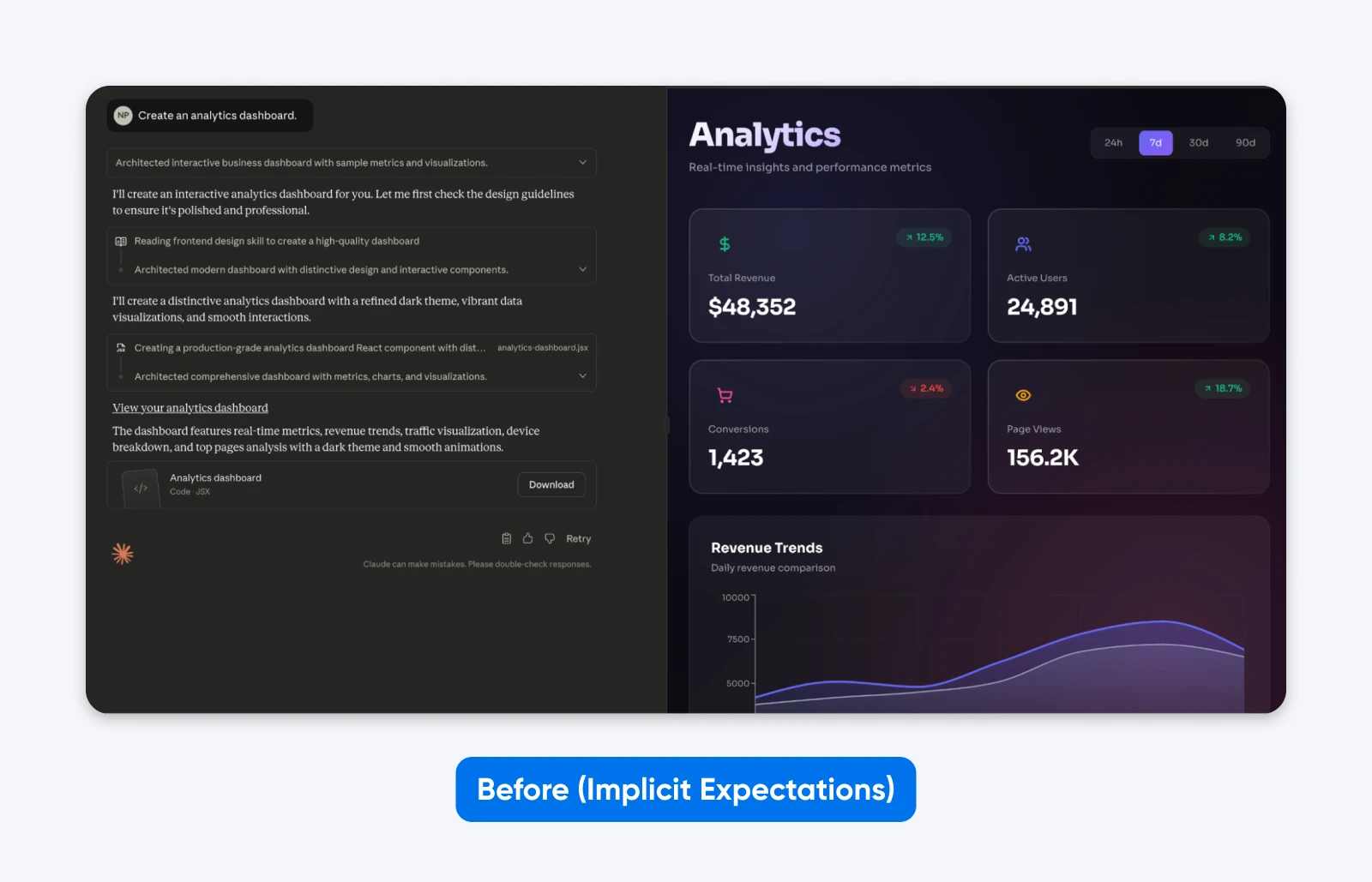
You’ll discover how this output is EXACTLY what we requested for. Whereas Claude took a little bit little bit of inventive freedom within the aesthetics, it has no performance.
After (express necessities):
Create an analytics dashboard. Embody as many related options and interactions as potential. Transcend the fundamentals to create a fully-featured implementation with knowledge visualization, filtering capabilities, and export features.
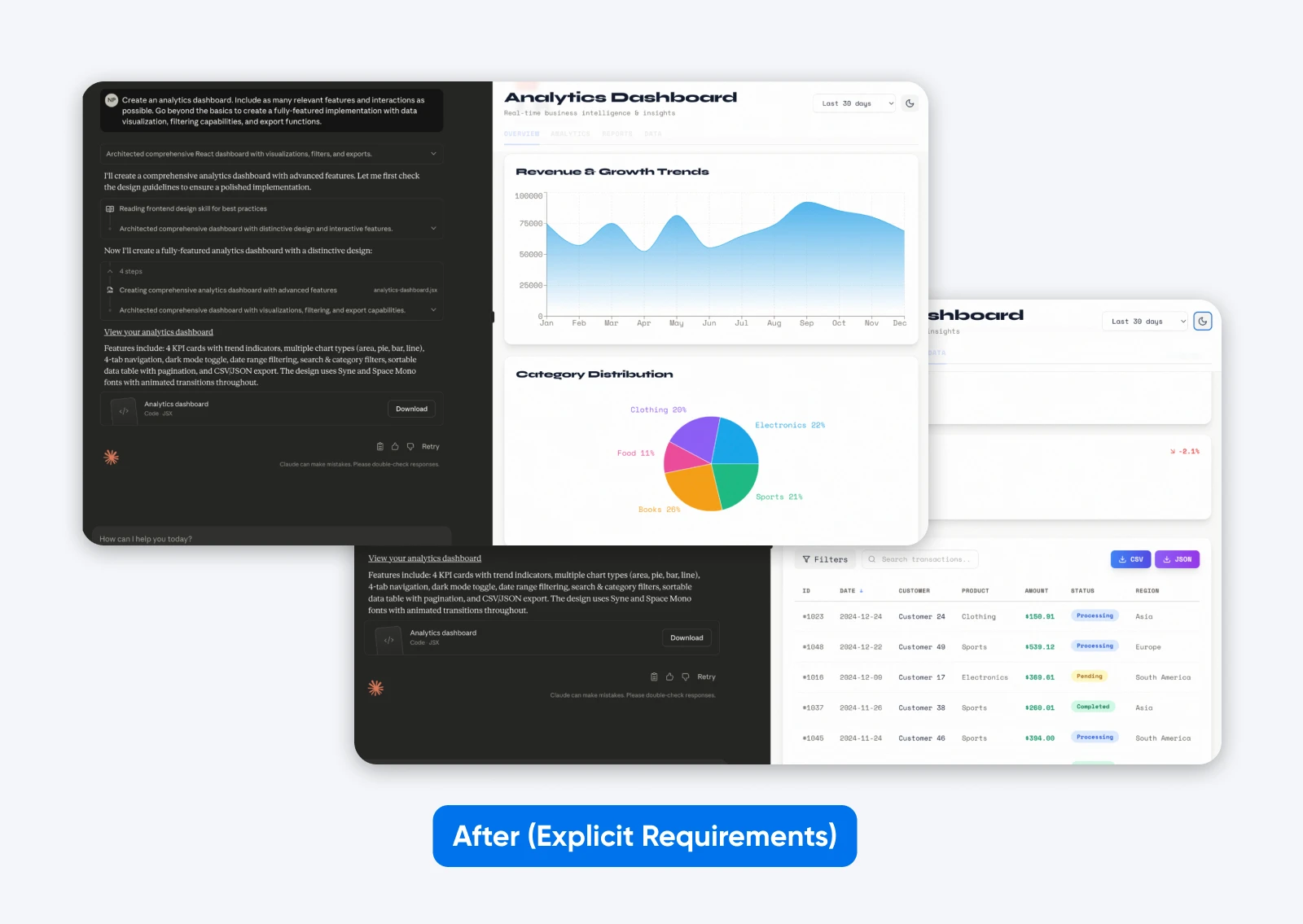
This second output with a extra descriptive immediate has extra options, a dashboard constructed on some dummy knowledge, which is each introduced graphically and in a tabular format, and it has tabs to separate all the information.
That’s what being particular does with the most recent Claude.
To make clear this level even additional, right here’s one other instance displaying how context improves instruction-following:
Earlier than (command with out context):
NEVER use ellipses in your response.
After (context-motivated instruction):
Your response will likely be learn aloud by a text-to-speech engine, so keep away from ellipses because the engine gained’t know find out how to pronounce them.
Key ideas for express directions:
- Outline what “complete” means to your particular job: Don’t assume Claude will infer high quality requirements.
- Clarify why guidelines exist fairly than simply stating them: Claude generalizes higher from motivated directions.
- Specify the output format explicitly: Request “prose paragraphs” as a substitute of hoping Claude gained’t default to bullet factors.
- Present concrete success standards: What does job completion seem like?
Effectiveness score: 9/10 throughout all job sorts.
4. Present Examples of What You Need
Few-shot prompting gives Claude with instance inputs and outputs demonstrating the specified conduct. This works, however solely when examples are top quality and task-appropriate, and the impression varies dramatically by use case.
Anthropic’s official steerage emphasizes:
“Claude 4.x fashions pay shut consideration to particulars and examples as a part of their exact instruction following. Guarantee your examples align with behaviors you need to encourage and reduce behaviors you need to keep away from.”
Anthropic recommends 3-5 various, related examples for complicated duties. Extra examples equals higher efficiency.
Right here’s an instance of what that appears like in apply:
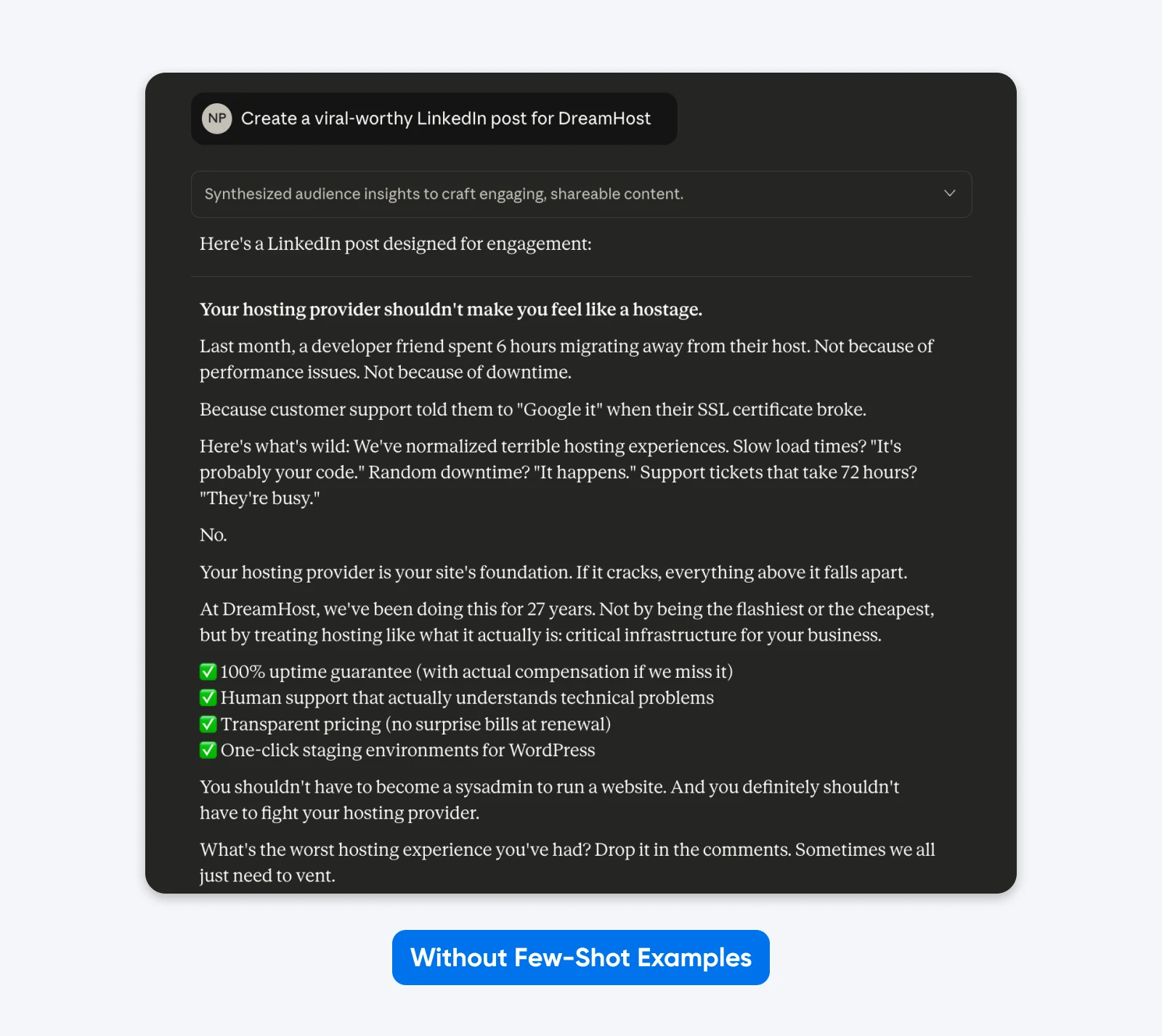
Right here, Claude took inventive freedom with format, emoji utilization, messaging, and tone. Generic company converse
Including examples works as a result of they present fairly than inform, whereas clarifying the refined necessities which are troublesome to specific by way of description alone.
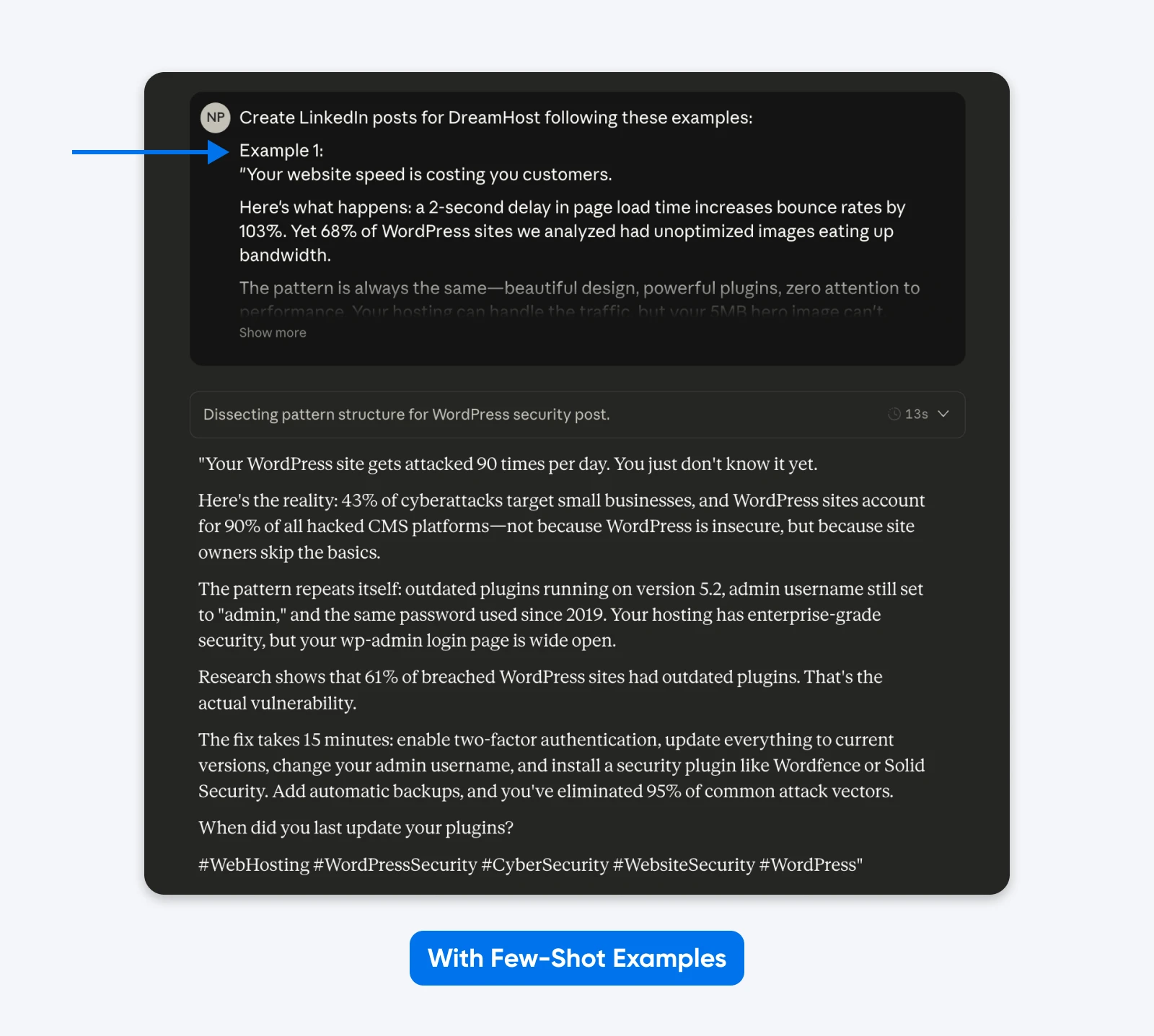
This output sticks extra carefully to the examples I’ve supplied within the immediate. You need to use the few-shot examples methodology to get LinkedIn posts like your best-performing ones. An educational paper on Finite State Machine (FSM) design confirmed structured examples achieved 90% success fee in comparison with directions with out examples.
Methods to Implement:
- Wrap examples in
tags, grouped in tags - Place examples early within the first person message
- Use 3-5 various examples for complicated duties
- Match each element in examples to desired output (Claude 4.x replicates naming conventions, code fashion, formatting, punctuation)
- Keep away from redundant examples
When Examples Work Greatest:
- Information formatting requiring exact construction
- Complicated coding patterns needing particular approaches
- Analytical duties demonstrating reasoning strategies
- Output requiring constant fashion and conventions
When to Skip: Easy queries the place directions suffice, or once you need Claude to make use of its personal judgment.
Effectiveness score: 10/10 for formatting duties, 6/10 for easy queries.
5. Put Context Earlier than Your Query
Claude has a 200,000-token context window (as much as 1 million in some circumstances) and might perceive queries positioned wherever within the context. However Anthropic’s documentation recommends inserting lengthy paperwork (20,000+ tokens) on the prime of prompts, earlier than queries.
Testing confirmed this improves response high quality by as much as 30% in comparison with query-first ordering, particularly with complicated, multi-document inputs.
Why? Claude’s consideration mechanisms weight content material towards the tip of prompts larger. Inserting the query after context lets the mannequin reference earlier materials whereas producing responses..
Earlier than (query-first):
Analyze the quarterly monetary efficiency and establish key tendencies.
[20,000 tokens of financial data]
After (context-first):
[20,000 tokens of financial data]
Based mostly on the quarterly monetary knowledge supplied above, analyze efficiency and establish key tendencies in income development, margin enlargement, and working effectivity. Give attention to actionable insights for govt decision-making.
When this issues: Lengthy-context evaluation the place Claude must reference earlier materials extensively.
When to Skip: Quick prompts below 5,000 tokens.
Effectiveness score: 8/10 for long-context duties, 4/10 for brief prompts.
What Prompting Methods Don’t Work Anymore: Busting Widespread Myths
Claude 4.5’s adjustments invalidated a number of standard strategies that labored with earlier fashions.
1. Emphasis Phrases (ALL CAPS, “MUST,” “ALWAYS”)
Writing in all caps now not ensures compliance. Chris Tyson’s evaluation discovered Claude now prioritizes context and logic over emphasis.
When you write “NEVER fabricate knowledge” however the context implies you want an estimate, Claude 4.5 prioritizes the logical want over your capitalized command.
Use conditional logic as a substitute:
- Dangerous: ALWAYS use precise numbers!
- Good: If verified knowledge is on the market, use exact figures. If not, present ranges and label them as estimates.
2. Handbook Chain-of-Thought Directions
Telling the mannequin to “assume step-by-step” wastes tokens when utilizing Prolonged Considering mode.
While you allow Prolonged Considering, the mannequin manages its personal reasoning funds. Including your individual “step-by-step” directions is redundant.
What to do as a substitute:
Belief the instrument. When you allow Prolonged Considering, take away all directions about find out how to assume.
3. Unfavourable Constraints (“Don’t Do X”)
Telling Claude precisely what to not do typically backfires.
Analysis on “Pink Elephant” directions exhibits that telling a sophisticated mannequin not to consider one thing will increase the chance it is going to deal with it.
Claude’s consideration mechanism highlights the forbidden idea, maintaining it lively within the context window.
As a substitute, reframe each damaging as a constructive command:
- Dangerous: Don’t write lengthy, fluffy introductions. Don’t use phrases like “delve” or “tapestry.”
- Good: Begin immediately with the core argument. Use concise, punchy language.
How To Migrate Prompts From Claude 3.5 to Claude 4?
When you’re migrating from Claude 3.5 to 4.5, you’ll be able to migrate your immediate library by following 5 systematic steps validated by developer expertise.
We are going to use a standard internet hosting situation for this instance. The objective is to generate a technical help response for a buyer experiencing a “503 Service Unavailable” error on their WordPress web site.

1. Audit Implicit Assumptions
Start by figuring out the place the immediate depends on the mannequin to guess the context. In older variations, the mannequin would infer you have been utilizing the most typical software program stack. Claude 4.5 is not going to make that leap.
Legacy Immediate:
“My web site is loading slowly and displaying errors. You might be an skilled server administrator. Assume step-by-step and inform me find out how to repair the configuration to make it sooner.”
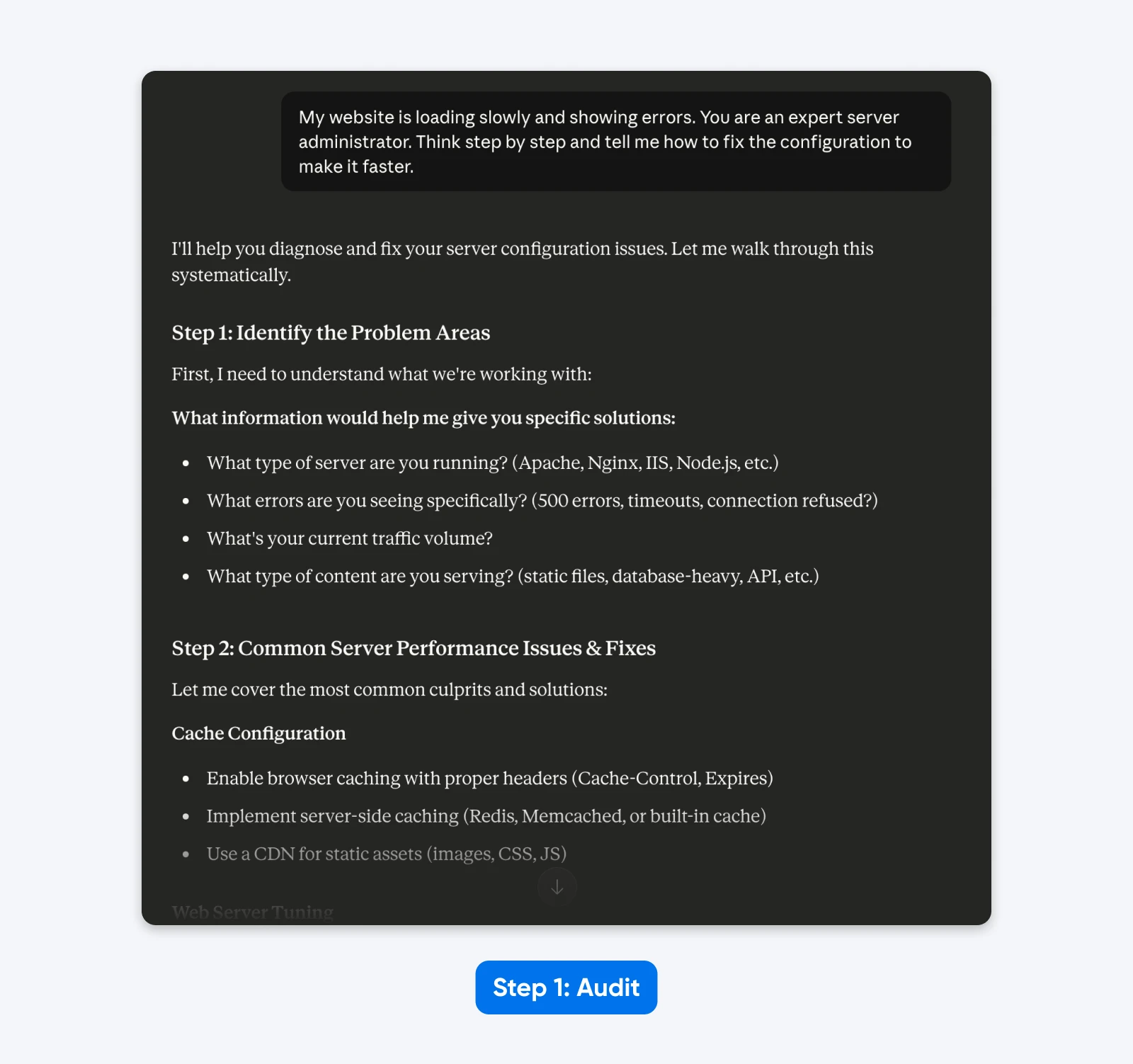
The Audit:
- “Web site” implies a generic setup fairly than a particular CMS (WordPress).
- “Slowly” is subjective; it may imply excessive Time to First Byte or sluggish asset rendering.
- “Errors” lacks the particular HTTP standing codes wanted for analysis.
- “Skilled server administrator” and “Assume step-by-step” are pointless steering directions.
Within the response, Claude 4.5 asks for extra info because it’s skilled to keep away from making assumptions.
2. Refactor for Specific Specificity
Now, rewrite the immediate to outline the atmosphere, the particular drawback, and the specified output format. You could provide the technical particulars the mannequin beforehand guessed.
Refactored Immediate:
“My WordPress web site operating on Nginx and Ubuntu 20.04 is experiencing excessive Time to First Byte (TTFB) and occasional 502 Dangerous Gateway errors. You might be an skilled server administrator. Assume step-by-step and supply particular Nginx and PHP-FPM configuration adjustments to resolve these timeouts.”

The Outcome: The immediate now specifies the precise software program stack (Nginx, Ubuntu, WordPress) and the particular error (502 Dangerous Gateway), lowering the prospect of irrelevant recommendation about Apache or IIS. And Claude responds with an evaluation and a step-by-step resolution.
3. Implement Conditional Logic
Claude 4.5 excels when given a choice tree. As a substitute of asking for a single static resolution, instruct the mannequin to deal with totally different situations primarily based on the information it analyzes.
Immediate with Logic:
“My WordPress web site operating on Nginx and Ubuntu 20.04 is experiencing excessive TTFB and 502 Dangerous Gateway errors. You might be an skilled server administrator. Assume step-by-step.
If the error logs present ‘upstream despatched too large header’, present configuration adjustments for buffer sizes. If the error logs present ‘upstream timed out’, present configuration adjustments for execution closing dates.”
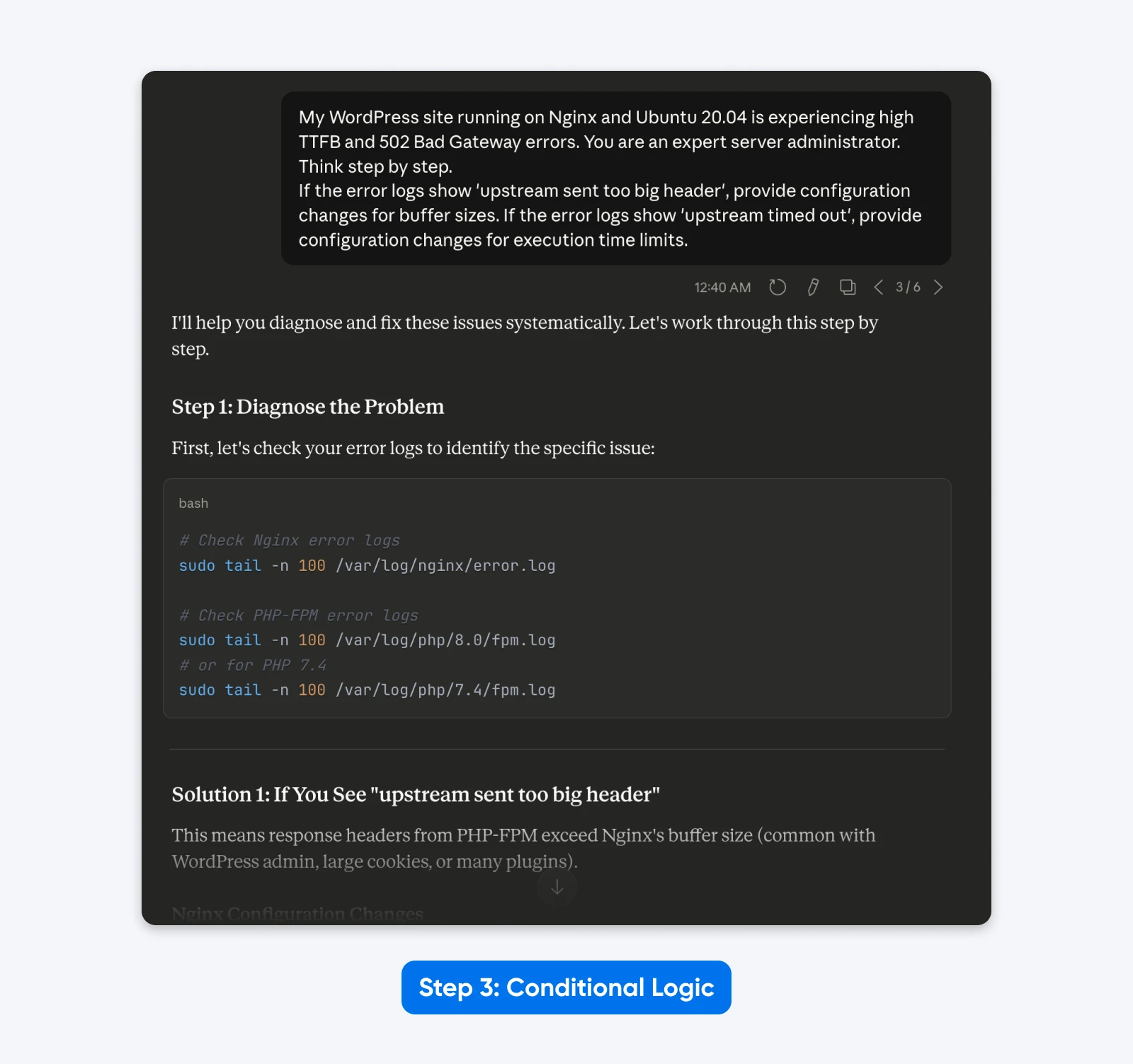
The Outcome: The output turns into dynamic. The mannequin gives focused options primarily based on the particular root trigger logic you outlined, fairly than a generic record of fixes.
4. Take away Outdated Steering Language
Legacy prompts typically comprise pondering directions that customers believed improved efficiency. These are pointless and redundant with Claude 4.5 because it has prolonged pondering.
Cleaned Immediate:
“My WordPress web site operating on Nginx and Ubuntu 20.04 is experiencing excessive TTFB and 502 Dangerous Gateway errors.
If the error logs present ‘upstream despatched too large header’, present configuration adjustments for buffer sizes. If the error logs present ‘upstream timed out’, present configuration adjustments for execution closing dates.”
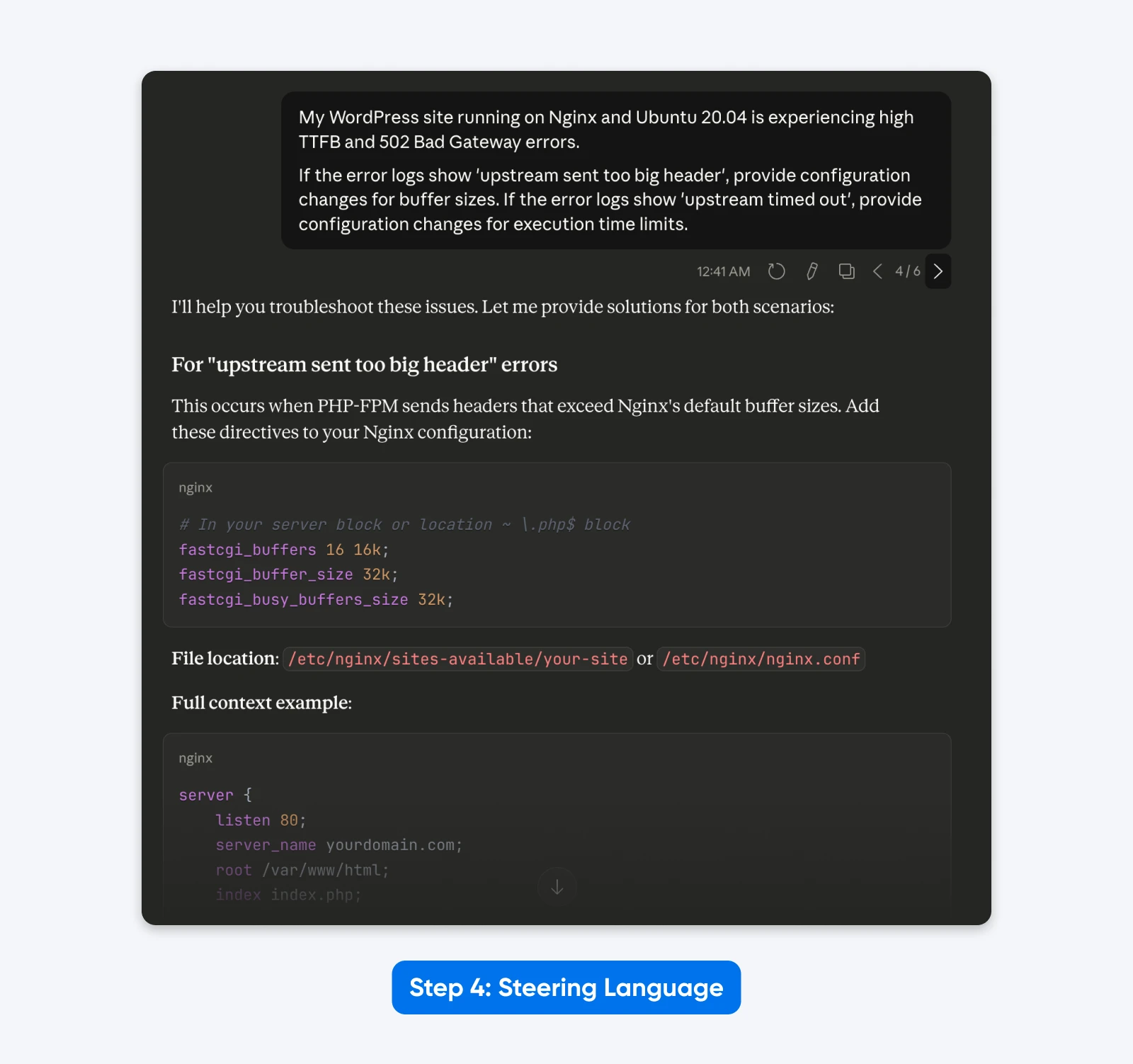
The Outcome: A leaner immediate that focuses purely on the technical job, eradicating the distraction of “You might be an skilled” and “Assume step-by-step.”
5. Check Systematically
Assemble the elements right into a structured format utilizing XML or clear headers. This matches the coaching knowledge of the mannequin and yields essentially the most constant outcomes.
ROLE: Linux System Administrator specializing in Nginx and WordPress efficiency.
TASK: Resolve 502 Dangerous Gateway errors and cut back Time to First Byte (TTFB) for a WordPress web site on Ubuntu 20.04.
LOGIC:
- If logs present 'upstream despatched too large header', enhance fastcgi_buffer_size and fastcgi_buffers.
- If logs present 'upstream timed out', enhance fastcgi_read_timeout in nginx.conf and request_terminate_timeout in www.conf.
OUTPUT REQUIREMENTS:
- Present precise configuration strains to vary.
- Clarify the impression of every change on server reminiscence.
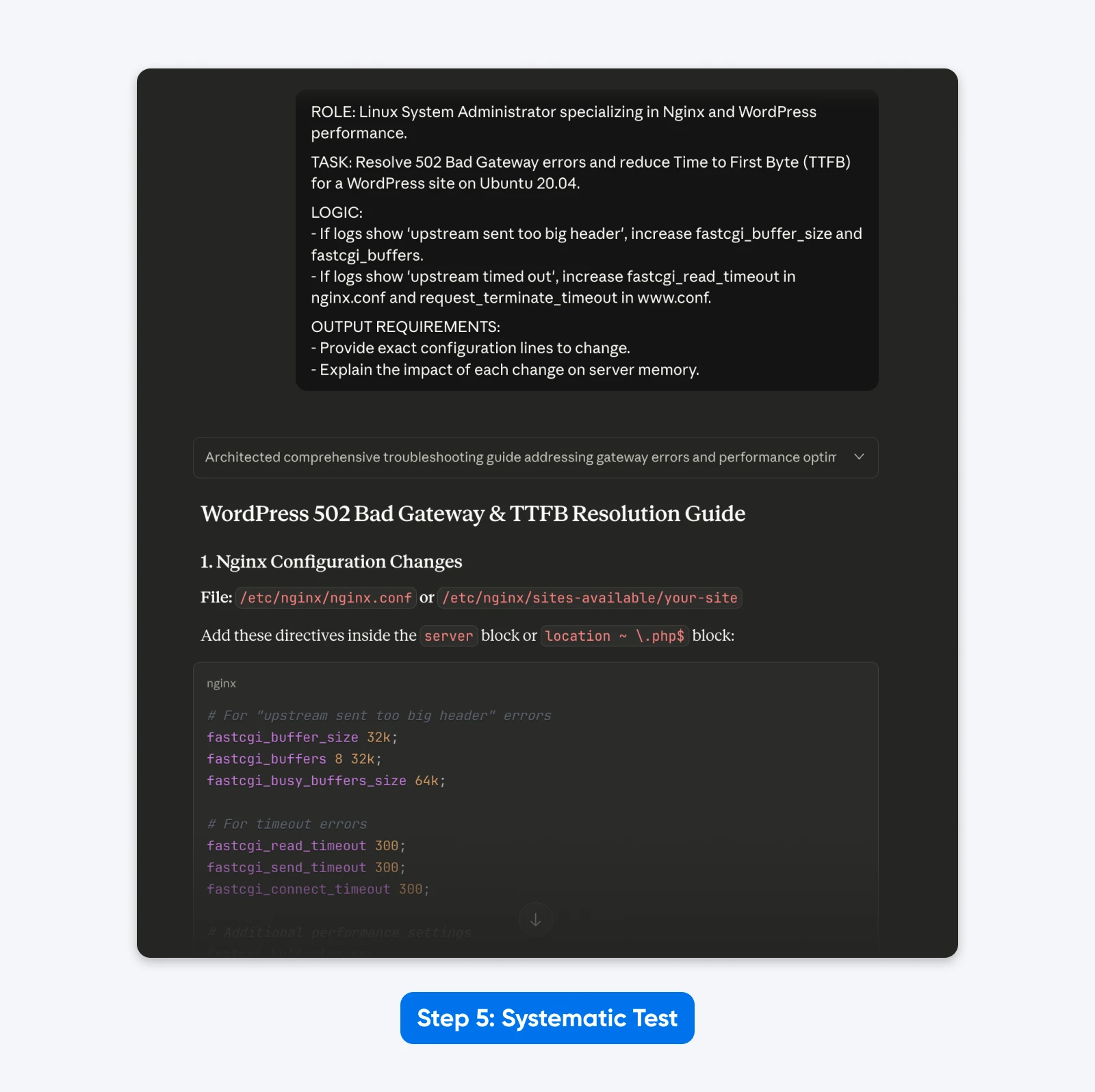
The Outcome: The response was extra structured, allowed me to unravel the issue with copy-pasteable config file knowledge as requested and defined the answer higher.
What This Means for Your Workflow
Claude 4.x fashions work otherwise from earlier fashions. They observe your precise directions as a substitute of assuming what you meant, which helps once you want constant outcomes. The trouble you spend on immediate engineering at first will repay for those who run the identical job repeatedly.
Every method on this information has been cherry-picked as a result of it aligns carefully with how Claude 4.x was constructed. XML tags, Prolonged Considering mode, express directions, few-shot examples, and a context-first method work as a result of, primarily based on Claude’s prompting guides and anecdotal proof, that’s possible how Anthropic has skilled the fashions.
So go forward, decide one or two strategies from this information and take a look at them in your precise workflows. Measure what adjustments and what strategies work in your favor. The perfect method is the one backed by actual knowledge from your individual day-to-day workflows.
Did you take pleasure in this text?


")

")




{kind=link}