
Node.js efficiency issues in manufacturing nearly all the time come from the identical quick checklist: a single-process app pinned to at least one CPU core, lacking caching layers, an occasion loop blocked by synchronous work, and a course of supervisor that crashes silently at 2 a.m.
This text covers the tuning that truly strikes p95 latency and concurrent request capability on a manufacturing VPS, with the configuration patterns that maintain up at actual site visitors.
Why Node.js Efficiency Tuning Issues on a Manufacturing VPS
A VPS offers you the foundation entry, devoted vCPU allocation, and chronic course of management that shared internet hosting can not, which is precisely what a long-running Node.js course of wants. The default node server.js setup runs your software as a single course of on a single thread, so a 4-vCPU VPS operating an untuned app makes use of roughly 25% of the {hardware} you’re paying for. Tuning closes that hole.
The opposite motive to tune on the VPS layer is that Node.js is single-threaded for software code by design. The runtime makes use of an occasion loop and a libuv thread pool to deal with I/O, however any CPU-bound work you write nonetheless blocks each request on that employee. Manufacturing tuning is generally about getting CPU-bound work off the occasion loop. It additionally includes placing cheaper layers in entrance of Node so the runtime solely handles what it should.
What Are the Most Widespread Node.js Efficiency Bottlenecks?
Actual manufacturing points cluster round a handful of root causes:
- Single-process deployments. One Node course of can not use a couple of CPU core for software code, so a multi-core VPS sits idle underneath load.
- Blocked occasion loop. Synchronous file reads, JSON.parse on giant payloads, bcrypt hashing on the primary thread, or unbounded regex stall each concurrent request.
- Reminiscence leaks from retained references. Lengthy-lived closures, rising in-memory caches with out eviction, and occasion listeners connected with out cleanup quietly push heap utilization previous the default 1.5 GB ceiling.
- No HTTP-level caching. Each request hits software code, even for responses that change as soon as an hour.
- Direct publicity to the web. Working node on port 80 or 443 with out Nginx in entrance leaves TLS termination, static file serving, and slow-client buffering to your software.
- Database spherical journeys on the new path. Lacking indexes and N+1 queries present up as Node efficiency issues regardless that the precise time is spent ready on the database.
Figuring out which one you could have requires measurement, not guessing. Begin by checking occasion loop lag and heap utilization earlier than altering something.
How Do You Set the Proper Node.js Cluster and Employee Depend?
The cluster sample runs one Node course of per CPU core, with a grasp course of distributing connections to employees. The Node.js cluster module is constructed into the runtime and is the muse that PM2 and most course of managers use underneath the hood.
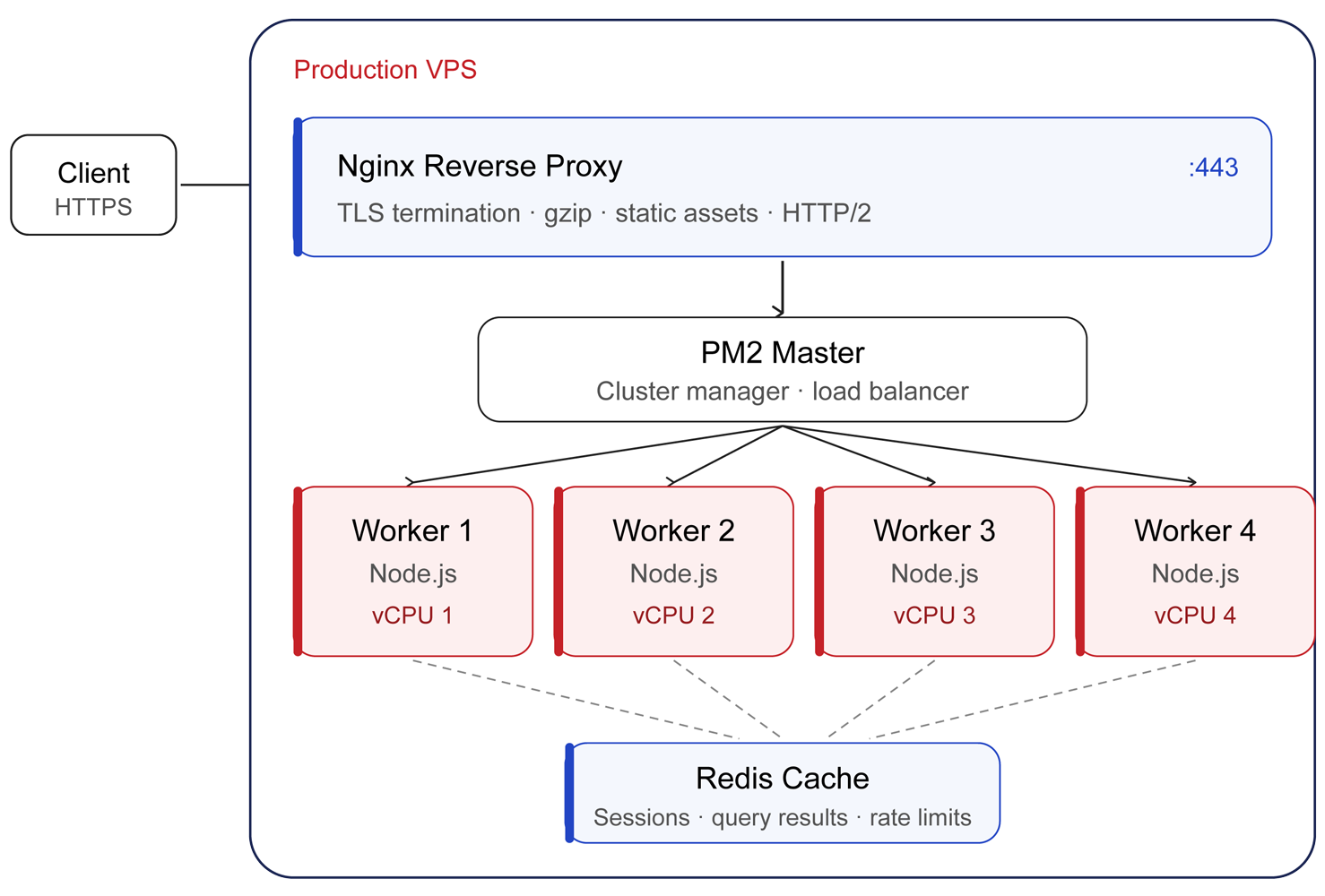
The final rule:
- CPU-bound or balanced workloads: employees = variety of vCPUs. On a 4-vCPU VPS, run 4 employees.
- I/O-heavy workloads: employees = vCPUs continues to be the proper start line. Including extra hardly ever helps, as a result of the bottleneck is the database or exterior API, not Node.
- Reminiscence-constrained VPS plans: employees = flooring(out there RAM / per-worker heap). If every employee holds 400MB of heap and you’ve got 2GB free after the OS, 4 employees is the ceiling no matter core rely.
With PM2 you set this declaratively:
pm2 begin app.js -i max --name apiThe -i max flag spawns one employee per out there core. Use a selected quantity, comparable to -i 4, whenever you wish to depart headroom for a database or cache course of on the identical VPS.
What PM2 and Course of Supervisor Settings Enhance Stability?
PM2 is the commonest manufacturing course of supervisor for Node, and the defaults will not be the configuration you need at scale. A production-ready ecosystem.config.js seems to be nearer to this:
module.exports = {
apps: [{
name: 'api',
script: './server.js',
instances: 'max',
exec_mode: 'cluster',
max_memory_restart: '500M',
node_args: '--max-old-space-size=460',
env_production: {
NODE_ENV: 'production',
PORT: 3000
},
error_file: '/var/log/pm2/api-err.log',
out_file: '/var/log/pm2/api-out.log',
merge_logs: true,
time: true
}]
};A couple of particulars that matter in manufacturing:
max_memory_restarttriggers a swish restart earlier than a employee hits the V8 heap restrict and will get killed by the OS OOM killer. Set it 5 to 10% under--max-old-space-size.exec_mode: clusteris what really allows load balancing throughout employees. Fork mode runs unbiased processes with out shared port binding.- Log rotation is just not on by default. Set up
pm2-logrotateand setpm2 setpm2-logrotate:max_size 50Mandpm2 set pm2-logrotate:retain 14so logs don’t fill the disk throughout a site visitors spike. - Startup persistence. Run
pm2 startup systemdandpm2 saveso employees come again mechanically after a reboot or kernel replace.
For zero-downtime reloads on deploys, use pm2 reload api quite than restart. Reload swaps employees one after the other whereas retaining the cluster on-line.
How Ought to You Configure Nginx as a Reverse Proxy for Node.js?
Placing Nginx in entrance of Node is the only most impactful change for many manufacturing deployments. Nginx handles TLS termination, static asset supply, gzip and Brotli compression, request buffering for sluggish purchasers, and HTTP/2 multiplexing, liberating Node to do solely the work your software code requires.
A minimal manufacturing server block:
uupstream node_api {
server 127.0.0.1:3000;
keepalive 64;
}
server {
hear 443 ssl http2;
server_name api.instance.com;
ssl_certificate /and many others/letsencrypt/dwell/api.instance.com/fullchain.pem;
ssl_certificate_key /and many others/letsencrypt/dwell/api.instance.com/privkey.pem;
gzip on;
gzip_types software/json textual content/css software/javascript;
location /static/ {
alias /var/www/api/public/;
expires 30d;
add_header Cache-Management "public, immutable";
}
location / {
proxy_pass http://node_api;
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_set_header Host $host;
proxy_set_header X-Actual-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 60s;
}
}Two particulars builders miss most frequently: setting proxy_http_version 1.1 plus the empty Connection header allows connection reuse from the upstream keepalive pool, which dramatically reduces TCP handshake overhead underneath load. Serving /static/ instantly from Nginx with lengthy Cache-Management headers additionally pulls hundreds of requests per minute off your Node employees for information they need to by no means have been touching.
What Reminiscence and Rubbish Assortment Flags Ought to You Tune?
Node makes use of V8 underneath the hood, and V8’s default old-generation heap measurement is roughly 1.5GB on 64-bit methods no matter how a lot RAM the VPS really has. On a 4GB VPS operating 4 employees, that default leaves about 10GB of theoretical heap capability you can’t use as a result of every employee caps itself.
The flag to set is --max-old-space-size, expressed in megabytes:
node --max-old-space-size=460 server.jsSizing steerage:
- Reserve roughly 25% of whole RAM for the OS, Nginx, and any database or cache operating on the identical VPS.
- Divide the remaining by your employee rely, then subtract 10% for V8 overhead. On a 2GB VPS with 4 employees, that math lands round 460MB per employee.
- Match
max_memory_restartin PM2 to this worth or barely under. A employee restarted by PM2 is recoverable; one killed by the kernel OOM killer is just not.
For very high-throughput companies, extra flags value testing embrace --max-semi-space-size to present the younger technology extra room (lowering minor GC frequency on companies that allocate aggressively) and --no-compilation-cache in case you are seeing reminiscence stress from cached compiled code in short-lived employees. Take a look at adjustments underneath load earlier than committing them to manufacturing.
How Do You Profile a Sluggish Node.js Utility?
Most efficiency work fails as a result of the engineer optimized the fallacious factor. Profile first, then change code:
node --inspect server.jswith Chrome DevTools offers you a flame graph of CPU time and a heap snapshot device for locating retained objects. The DevTools Efficiency tab is the quickest path to figuring out a blocked occasion loop.clinic physician(clinicjs.org) runs your app underneath load and produces a analysis. It’s particularly good at flagging occasion loop delay and extreme GC stress earlier than you dig deeper.autocannonis the load generator most Node builders attain for. A baseline benchmark earlier than any tuning offers you the comparability level you should know in case your adjustments helped or damage.- Occasion loop lag monitoring in manufacturing belongs in your APM or a easy
perf_hooks.monitorEventLoopDelay()exporter to Prometheus. Lag above 50 ms underneath regular load is a sign that one thing synchronous is obstructing employees.
If a single endpoint is sluggish, time the database question individually from the handler. The Node profiler will level at await pool.question(...) because the sluggish line, however the work is going on in PostgreSQL or MySQL, not in your code.
Which Caching Layers Make the Greatest Distinction?
Caching is the highest-ROI optimization most groups skip. Three layers matter for Node.js manufacturing workloads:
- Utility-level caching with Redis. Transfer session storage, rate-limit counters, and incessantly accessed question outcomes out of the database into Redis on the identical VPS or a personal community neighbor. A spherical journey to native Redis is sub-millisecond; the identical question towards PostgreSQL on chilly cache could be 20 to 80 ms.
- HTTP response caching at Nginx. For endpoints that return equivalent responses for a similar URL,
proxy_cachein Nginx can serve hundreds of requests per second from disk with out ever touching Node. Even a 10-second cache window on a preferred endpoint cuts upstream load dramatically. - CDN in entrance of your VPS. Cloudflare, Bunny, or any reverse proxy CDN absorbs static asset site visitors, terminates TLS on the edge, and shields the origin from bot site visitors. For globally distributed customers, the latency enchancment is normally bigger than any application-level tuning.
The order so as to add them is the order listed. Redis first as a result of it adjustments how your software is structured. Nginx caching second as a result of it requires no code adjustments, and a CDN third as a result of it advantages even an untuned app.
How Do You Safe a Manufacturing Node.js VPS?
Efficiency and safety overlap greater than builders anticipate, as a result of an uncovered software is one botnet scan away from being unavailable. Baseline hardening for a Node.js VPS:
- Run Node as a non-root consumer. Use
setcap 'cap_net_bind_service=+ep' $(which node)if you should bind to ports under 1024 with out root, or terminate at Nginx and let Node hear on 3000. - Configure a number firewall. UFW on Ubuntu or
firewalldon AlmaLinux locks the server all the way down to solely the ports you deliberately expose, sometimes 22, 80, and 443. - Preserve dependencies patched.
npm auditin CI and Dependabot or Renovate on the repository catch CVEs in transitive dependencies earlier than they attain manufacturing. - Set HTTP safety headers. Helmet is the usual Categorical middleware for headers like
Strict-Transport-Safety,Content material-Safety-Coverage, andX-Body-Choices. Misconfigured headers are one of many extra widespread findings in safety audits. - Rotate secrets and techniques and use surroundings variables. By no means commit .env information. Instruments like Doppler, Vault, and even systemd
EnvironmentFile=directives maintain credentials out of the repository.
When Ought to You Scale Past a Single VPS?
A well-tuned Node.js software on a 4 to eight vCPU VPS with Nginx and Redis can comfortably serve hundreds of thousands of requests per day. Scaling horizontally normally turns into needed for considered one of three causes:
- Sustained CPU utilization above 70% throughout all employees, even after profiling and caching adjustments, signifies you could have outgrown the field.
- Tight uptime SLAs that can’t tolerate a single-host failure require at the least two software VPS situations behind a load balancer.
- Stateful useful resource separation turns into well worth the operational price when your database, cache, and software workloads begin competing for a similar disk I/O or RAM on a shared VPS.
InMotion’s Cloud VPS plans and Managed VPS plans each ship with full root entry, devoted vCPU allocation, and Linux distributions together with AlmaLinux 9, Ubuntu 22.04 LTS, and Debian 12, which cowl the runtime necessities for any present Node.js LTS launch. The 99.99% uptime SLA and 24/7 entry to the APS staff matter most on the level the place your software has stopped being a facet undertaking and began carrying income.
In case you are operating a manufacturing Node.js software on shared internet hosting or on a VPS that has not been tuned previous the defaults, the adjustments on this article will probably minimize p95 latency in half. They’ll additionally double sustainable request throughput earlier than you spend one other greenback on infrastructure. Begin with PM2 cluster mode and Nginx in entrance, profile what’s left, and add caching the place the info helps it.
Sensible Node.js efficiency tuning for manufacturing VPS internet hosting, together with clustering, PM2, Nginx reverse proxy, reminiscence flags, and caching layers.
Able to Run Node.js in Manufacturing? InMotion’s Managed VPS plans provide you with root entry, devoted vCPU allocation, and a selection of AlmaLinux 9, Ubuntu 22.04 LTS, or Debian 12. Backed by 24/7 human assist and a 99.99% uptime SLA.






")

{kind=link}